Python 爬虫教程 01

1.浏览器
1.1 获取页面信息
进入要爬取的页面,按F12进入开发者模式: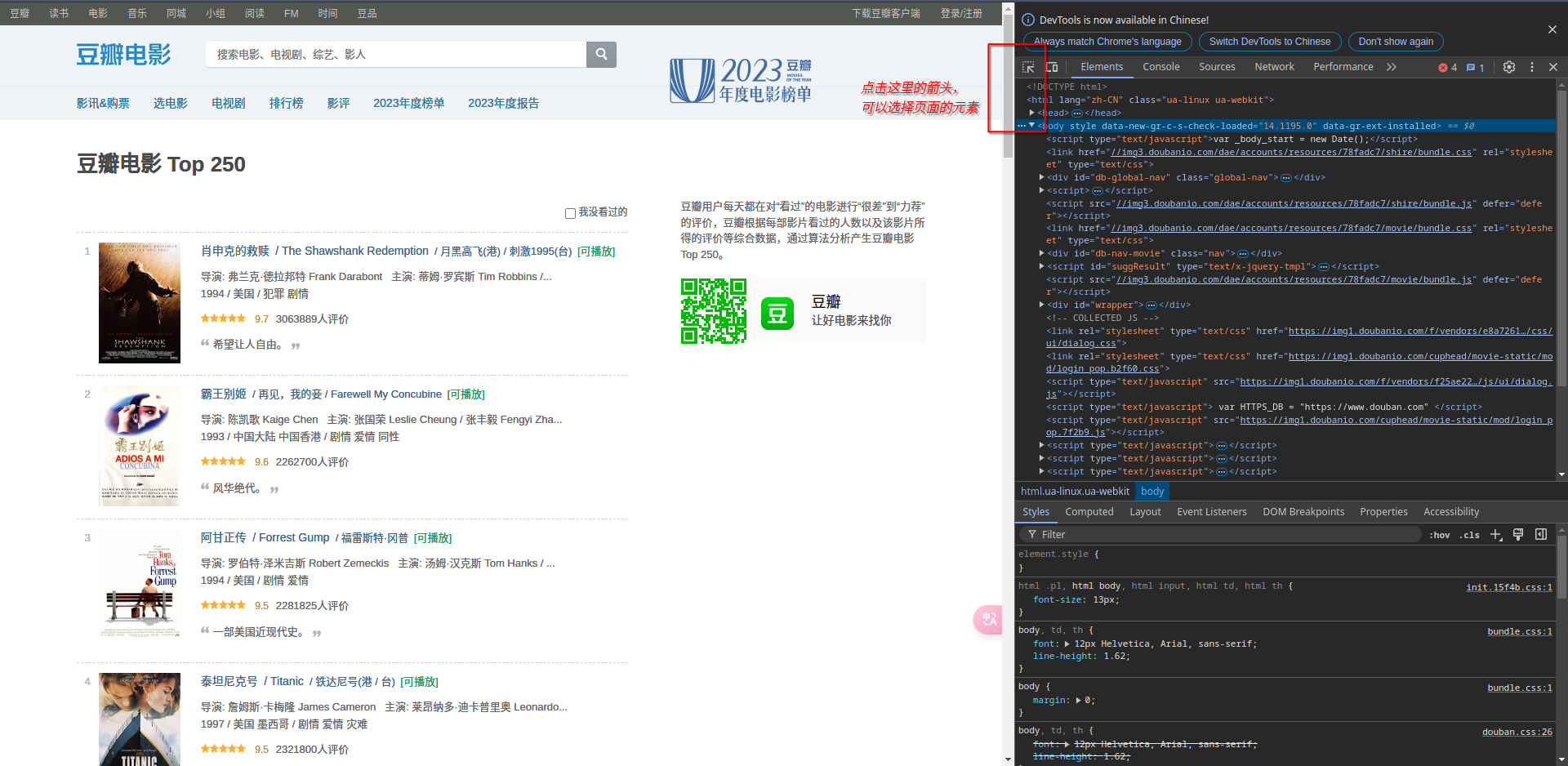
选择network一栏,左上角有一个红点标识暂停的意思,通过刷新页面可以获得当前页面的流量,但是对我们来说最重要的是top250?start=这个信息,正好与该网址https://movie.douban.com/top250?start=最后一部分的站点相对应。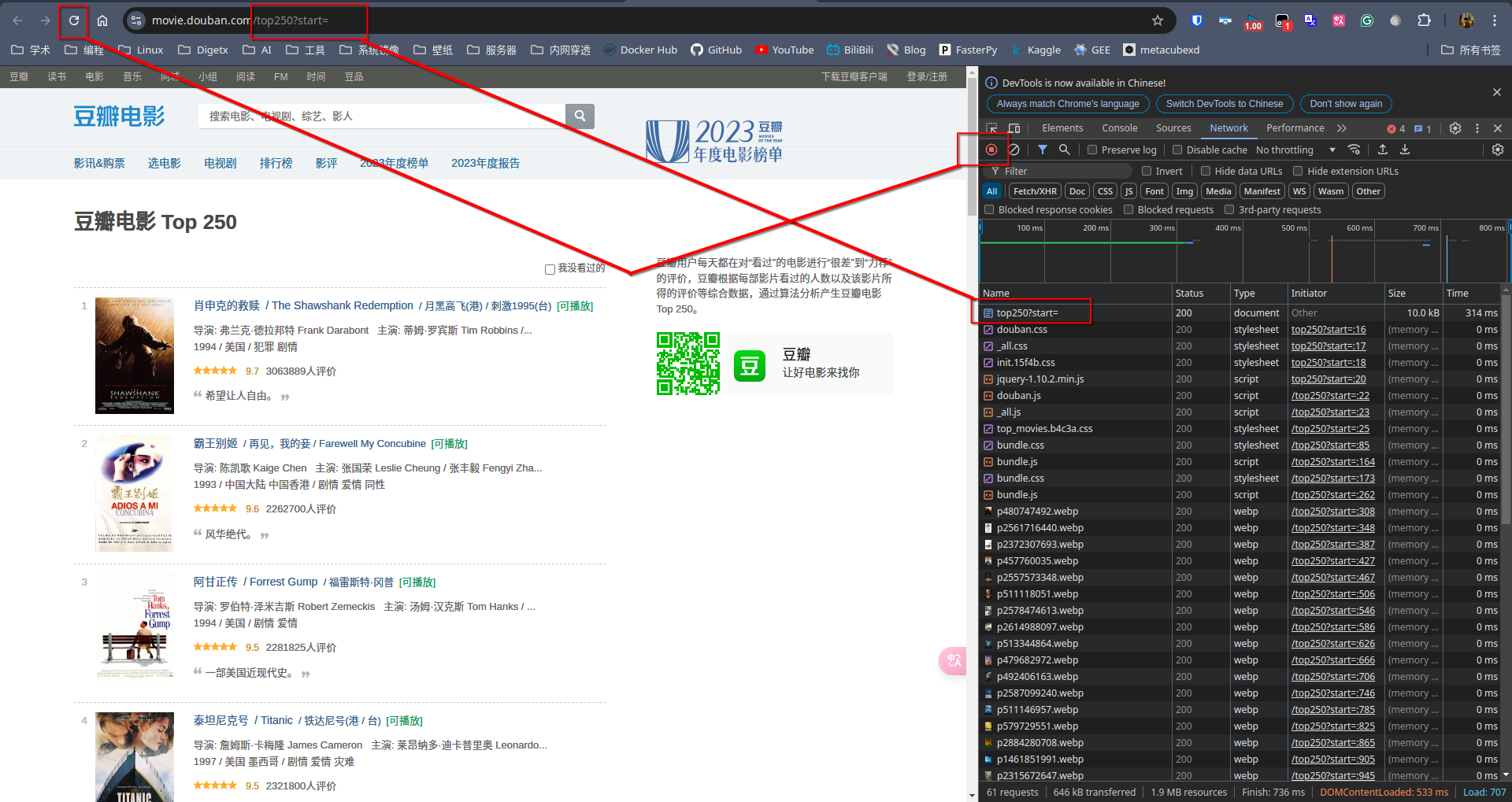
选择top250?start=这块,这部分内容主要是用于我们伪装自己的爬虫程序为浏览器(相当于把Python伪装成Chrome浏览器)。尤其是User-Agent部分。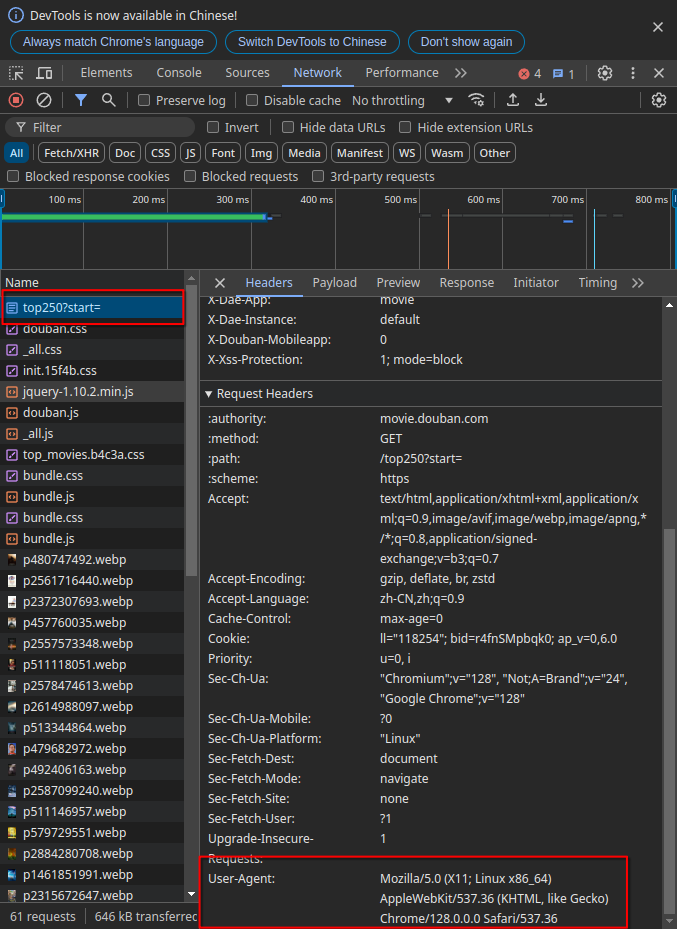
2.配置爬虫编程环境
- 创建虚拟环境
1
conda create -n scrapy python
- 激活:
1
conda activate scrapy
- 安装必要的包:
1
pip install pandas bs4 urllib xlwt sqlite3
3.urllib 包讲解
需要导入这两个类:
1 | import urllib.parse |
3.1 get 请求
获取一个百度的get请求,然后把内容保存到baidu.html文件中:
1 | # 发送一个 HTTP GET 请求,访问百度首页 |
用浏览器打开baidu.html文件,可以发现它就是百度搜索的页面。
这里的read()方法返回的是网页的字节数据(bytes类型),即网页的 HTML 源代码。这是因为读取的是未经解码的二进制数据。open方法中传入参数的参数是wb (write binary),该模式用于打开文件进行写入,且文件以二进制模式打开。由于response.read()返回的是字节数据(非文本),所以使用二进制模式写入文件。
3.2 post 请求
测试网址为:https://httpbin.org/post:
1 | # 将字典 {"hello": "world"} 编码为查询字符串 'hello=world' |
输出结果:
1 | { |
从输出结果可以看出在请求时伪装成了浏览器的样子。
POST 请求在 Web 开发中非常常用,通常用于向服务器提交数据,比如表单提交、文件上传、新数据的创建等。在发送 POST 请求时,服务器期望接收到的数据会放在请求的主体(body)中,而不是像 GET 请求那样附加在 URL 的查询字符串中。这也是需要通过 data 参数来封装发送给服务器的数据的原因。
3.2.1 POST 请求的用途
- 提交表单数据: 用户在网页上填写表单,并点击提交按钮,浏览器会向服务器发送一个
POST请求,表单中的数据会通过POST请求的主体发送。 - 上传文件: 文件上传通常通过
POST请求,文件数据被封装在请求主体中传递给服务器。 - 创建或修改资源: 比如在 REST API 中,
POST请求常用于向服务器创建新的资源,发送 JSON 或 XML 格式的数据。 - 提交敏感数据: 由于
POST请求的数据不在 URL 中,而是在请求主体中,适合传递一些敏感信息,如密码、个人数据等(但仍需结合 HTTPS 保障安全性)。
3.2.2 封装数据的用途
- 在
POST请求中,服务器期望从请求的 主体 接收数据。因此,数据必须通过data参数以字节(bytes)形式发送。 - 如果不提供
data参数,urllib.request.urlopen()默认发送的是一个GET请求(即不携带数据),而GET请求不能用于修改资源,只能用于获取资源。这时,访问像https://httpbin.org/post这种只能处理POST请求的 API,服务器会返回HTTP 405错误,表示METHOD NOT ALLOWED(方法不被允许),因为服务器只允许POST,不允许GET。 - 将数据通过
bytes封装后,urlopen方法知道你正在发送的是一个POST请求,而不是GET请求。
3.2.3 将数据封装为 bytes 的原因
在发送 POST 请求时,数据会被放在 HTTP 请求的主体中,HTTP 协议规定传输的数据以字节(bytes)的形式发送,因此你需要先将数据转换为 bytes 格式。Python 的 urllib.parse.urlencode() 函数将字典编码为查询字符串格式,然后将其通过 bytes() 转换为字节流。
3.3 超时处理
以get请求为例:
1 | try: |
3.4 查看响应
1 | response = urllib.request.urlopen("http://www.baidu.com") |
输出结果为200, 表示 HTTP 请求成功,服务器正常处理并返回了所请求的资源。HTTP 状态码是服务器在处理客户端请求后返回的标准响应代码。
常见的 HTTP 状态码:
2xx(成功类状态码):200 OK:请求成功并返回资源。201 Created:请求成功且服务器创建了新的资源。
3xx(重定向类状态码):301 Moved Permanently:资源已永久移动到新位置。302 Found:资源临时移动到新位置。
4xx(客户端错误类状态码):400 Bad Request:请求无效,通常是由于请求格式错误。401 Unauthorized:未经授权,通常是未提供认证信息。404 Not Found:服务器无法找到请求的资源。418:表示访问的网站有反爬虫机制,解决方法就是带请求头header(suser-agent)访问。
5xx(服务器错误类状态码):500 Internal Server Error:服务器内部错误。503 Service Unavailable:服务器暂时无法处理请求,通常是因为过载或维护。
查看响应内容:
1 | response = urllib.request.urlopen("http://baidu.com") |
输出结果:
1 | [('Date', 'Tue, 17 Sep 2024 15:43:39 GMT'), ('Server', 'Apache'), ('Last-Modified', 'Tue, 12 Jan 2010 13:48:00 GMT'), ('ETag', '"51-47cf7e6ee8400"'), ('Accept-Ranges', 'bytes'), ('Content-Length', '81'), ('Cache-Control', 'max-age=86400'), ('Expires', 'Wed, 18 Sep 2024 15:43:39 GMT'), ('Connection', 'Close'), ('Content-Type', 'text/html')] |
这个输出结果正好就是对应网页(这里是baidu)的响应头。如图所示: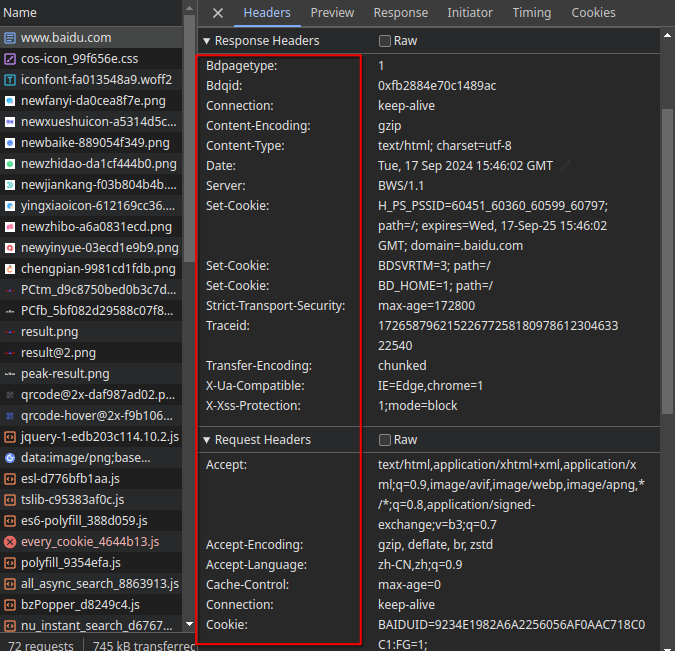
3.5 把访问伪装成浏览器
user-agen的信息需要在浏览器中按F12后,在对应页面的响应头中找到。
1 | url = "https://douban.com" |
这样的话就能获得该网址的页面信息。
这里并不是必须封装 data的,因为我们 不需要向豆瓣发送数据 ,因此可以不传递 data 参数,但这会导致 urllib.request.Request() 默认使用 GET 方法而不是 POST 方法。
如果使用 GET 请求的话,需要注意 GET 请求的特点是将数据 附加在 URL 后面 作为查询字符串,而不是放在请求体中。因此,GET 请求一般不用于提交大量数据,且不适合提交敏感数据。
可以将数据拼接到 URL 中,比如这样:
1 | url = "https://douban.com?name=eric" |
这种形式会将参数
name=eric 直接放到 URL 后面,形成一个完整的查询 URL。
4.bs4 包讲解
BeautifulSoup 通过解析 HTML 或 XML,将其转换成 Python 对象树,方便开发者使用各种方式来查找和操作数据,比如通过标签、类名、属性等。
需要导入这个类:
1 | from bs4 import BeautifulSoup |
主要功能
- 解析 HTML/XML 文档 :将 HTML 或 XML 文档解析成树形结构,便于操作。
- 提取数据 :提供多种方法,如通过标签、类名、属性来查找和筛选网页内容。
- 格式化输出 :可以格式化 HTML 文档,使其更易于阅读。
- 修复格式问题 :它能处理不规范的 HTML 代码,并生成结构化的输出。
常用方法
find(tag, **kwargs):找到符合条件的第一个标签。find_all(tag, **kwargs):找到所有符合条件的标签。select(css_selector):通过 CSS 选择器查找元素。get(attribute):获取标签的某个属性值。text:获取标签的文本内容。
4.1 获取标签及其里的内容
这里的测试文件是我们在3.1 get 请求章节中获得的baidu首页。
1 | file = open("course/test/baidu.html", "rb") |
这里向BeautifulSoup传入的参数有两个,第一个参数html表示指定文档类型,因为BeautifulSoup还能解析json、xml这类文件。第二个参数"html.parser表示指定解析器的类型。返回的对象bs中就存储有解析后的结果,后续操作也是对bs进行。
- 获取标签及其里面的内容
比如:
1 | print(bs.title) # 标签里的内容 |
输出结果:
1 | <title>百度一下,你就知道</title> |
直接就把文档里的title给拿出来了。
再比如执行:
1 | print(bs.a) |
输出结果:
1 | <a class="toindex" href="/">百度首页</a> |
就把文档里的a的内容给拿出来了。
我们可以发现规律,当用这种方式访问查找的时候,它会把文件中出现的 第一个 标签返回给你。
如果还是不清楚的话,我们可以尝试打印下该返回对象的类型:
1 | print(type(bs.a)) |
输出结果:
1 | <class 'bs4.element.Tag'> |
可以看出返回类型就是 标签(Tag) 。
如果我们在打印的对象后面加上限定:
1 | print(bs.title.string) |
输出结果:
1 | 百度一下,你就知道 |
只会返回标签里的内容。
把标签里的内容以字典的方式保存:
1 | print(bs.a.attrs) |
输出结果:
1 | {'class': ['toindex'], 'href': '/'} |
这是对应的找到的源文件内容的那行<a class="toindex" href="/">百度首页</a>,可以发现是以字典的形式返回给我们的。
4.2 文档的遍历
1 | print(bs.head.contents) |
输出结果:返回的是一个列表,如图所示
既然我们知道返回的是一个列表,那么我们就可以通过下标来访问:
1 | print(bs.head.contents[0]) |
想了解更多内容可以通过在浏览器搜索 遍历文件树 获知。w
4.3 文档的搜索
字符串过滤: 会查找与字符串完全匹配的内容
1
t_list = bs.find_all("a")
这表示查找所有的
a。会把所有符合a标签的以列表的形式存储。正则表达式搜索: 使用
search方法来匹配内容1
2
3
4import re # 正则表达式解析库
t_list = bs.find_all(re.compile("a"))
print(t_list)这种方式会把包含
a的内容(包括标签和文本内容)以列表的形式存储。以方法形式: 传入一个函数(方法),根据函数的要求搜索
1
2
3
4
5
6
7def name_is_exist(tag):
return tag.has_attr("name")
t_list = bs.find_all(name_is_exist)
for item in t_list:
print(item)在
find_all()中使用自定义筛选函数时,函数会对每个标签对象进行评估。函数的返回值必须是True或False。如果函数返回True,这个标签会被包含在返回结果中;如果返回False,则跳过该标签。has_attr()是BeautifulSoup的一个方法,用于检查某个标签是否具有指定的属性。在这个例子中,tag.has_attr("name")用来判断标签是否有name属性。kwargs : 指定参数来搜索
1
t_list = bs.find_all(id="head")
会把
id=head的标签存放到t_list列表中。
还比如:
1 | t_list = bs.find_all(class_ =True) |
这会把所有包含class的标签搜索出来。为什么要写成class_呢?因为class是 Python 保留关键字,保留关键字是不能之际作为参数名来使用的。
string 参数: 搜索出指定参数
1
2t_list = bs.find_all(string =["hao123", "地图", "贴吧"])
print(t_list)输出结果:
1
['hao123', '地图', '贴吧', '贴吧', '地图']
这种方式还可以应用正则表达式来查找包含特定文本的内容,也就是标签里的字符串。
比如这样:1
2
3import re
t_list = bs.find_all(string =re.compile("\d"))css选择器: 用
select()方法
通过标签来查找:
1 | t_list = bs.select("title") |
通过类名来查找:
1 | t_list = bs.select(".mnav") |
在 CSS 中,.(点号)表示选择具有特定类名的元素。.mnav表示选择所有class="mnav"的元素。
5.re 包讲解
Python 的 re 包用于处理正则表达式(Regular Expressions),它提供了在字符串中进行模式匹配、替换、拆分等操作的功能。正则表达式是一种强大的工具,可以用来查找、匹配和操作字符串中的特定模式。
5.1 re 包的常用方法
re.match():
- 作用:从字符串的起始位置开始匹配正则表达式。
- 如果匹配成功,返回一个
Match对象;如果不匹配,返回None。 - 示例:
1
2
3import re
result = re.match(r'\d+', '123abc456')
print(result.group()) # 输出: '123'
re.search():
- 作用:扫描整个字符串,找到第一个符合正则表达式的匹配项。
- 如果匹配成功,返回一个
Match对象;如果不匹配,返回None。 - 示例:
1
2result = re.search(r'\d+', 'abc123xyz456')
print(result.group()) # 输出: '123'
re.findall():
- 作用:返回字符串中所有与正则表达式匹配的部分,结果是一个列表。
- 示例:
1
2result = re.findall(r'\d+', 'abc123xyz456')
print(result) # 输出: ['123', '456']
re.finditer():
- 作用:返回一个迭代器,生成字符串中所有匹配的
Match对象。 - 示例:
1
2
3matches = re.finditer(r'\d+', 'abc123xyz456')
for match in matches:
print(match.group()) # 输出: '123' '456'
- 作用:返回一个迭代器,生成字符串中所有匹配的
re.sub():
- 作用:将匹配的部分替换为指定的字符串。
- 示例:
1
2result = re.sub(r'\d+', 'NUMBER', 'abc123xyz456')
print(result) # 输出: 'abcNUMBERxyzNUMBER'
re.split():
- 作用:根据正则表达式匹配的部分分割字符串,返回列表。
- 示例:
1
2result = re.split(r'\d+', 'abc123xyz456')
print(result) # 输出: ['abc', 'xyz', '']
re.compile():
- 作用:将正则表达式编译成正则对象,以便多次复用。
- 示例:
1
2
3pattern = re.compile(r'\d+')
result = pattern.findall('abc123xyz456')
print(result) # 输出: ['123', '456']
5.2 正则表达式的常用操作符
.(点号):匹配任意单个字符(除换行符\n之外)。- 示例:
a.b可以匹配acb,a9b, 但不能匹配ab。
- 示例:
^(脱字符):匹配字符串的开头。- 示例:
^a可以匹配abc中的a,但不能匹配bca。
- 示例:
$(美元符号):匹配字符串的末尾。- 示例:
a$可以匹配bca中的a,但不能匹配abc。
- 示例:
*(星号):匹配前一个字符 0 次或多次。- 示例:
ab*可以匹配a,ab,abb,abbbbb。
- 示例:
+(加号):匹配前一个字符 1 次或多次。- 示例:
ab+可以匹配ab,abb,abbbbb,但不能匹配a。
- 示例:
?(问号):匹配前一个字符 0 次或 1 次。- 示例:
ab?可以匹配a,ab,但不能匹配abb。
- 示例:
{m}:匹配前一个字符 正好 m 次。- 示例:
a{3}只能匹配aaa。
- 示例:
{m,n}:匹配前一个字符 至少 m 次,至多 n 次。- 示例:
a{2,4}可以匹配aa,aaa,aaaa。
- 示例:
[](字符集):匹配字符集中的任意一个字符。- 示例:
[abc]可以匹配a,b,c中的任意一个。
- 示例:
|(管道符号):表示“或”运算符,匹配左边或右边的内容。- 示例:
a|b可以匹配a或b。
- 示例:
\(反斜杠):用于转义特殊字符或表示特殊序列。- 示例:
\d匹配任意数字字符,\s匹配任意空白字符,\w匹配任意单词字符(字母、数字、下划线)。
- 示例:
()(括号):用于分组,或提取匹配的子字符串。- 示例:
(abc)+可以匹配abc,abcabc等。 - 提取示例:
1
2result = re.search(r'(abc)(\d+)', 'abc123')
print(result.groups()) # 输出: ('abc', '123')
- 示例:
5.3 常用的特殊序列
\d:匹配任何数字字符,等价于[0-9]。\D:匹配任何非数字字符,等价于[^0-9]。\s:匹配任何空白字符(空格、制表符等)。\S:匹配任何非空白字符。\w:匹配任何单词字符(字母、数字、下划线),等价于[a-zA-Z0-9_]。\W:匹配任何非单词字符,等价于[^a-zA-Z0-9_]。
5.4 实际应用示例
匹配电子邮件地址:
1
2
3
4email_pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
email = "contact@example.com"
if re.match(email_pattern, email):
print("Valid email")替换字符串中的数字:
1
2
3text = "My phone number is 12345"
result = re.sub(r'\d+', '#####', text)
print(result) # 输出: "My phone number is #####"
- Title: Python 爬虫教程 01
- Author: loskyertt
- Created at : 2024-09-17 12:25:45
- Updated at : 2025-02-17 04:36:55
- Link: https://redefine.ohevan.com/2024/09/17/01Python爬虫/
- License: This work is licensed under CC BY-NC-SA 4.0.
